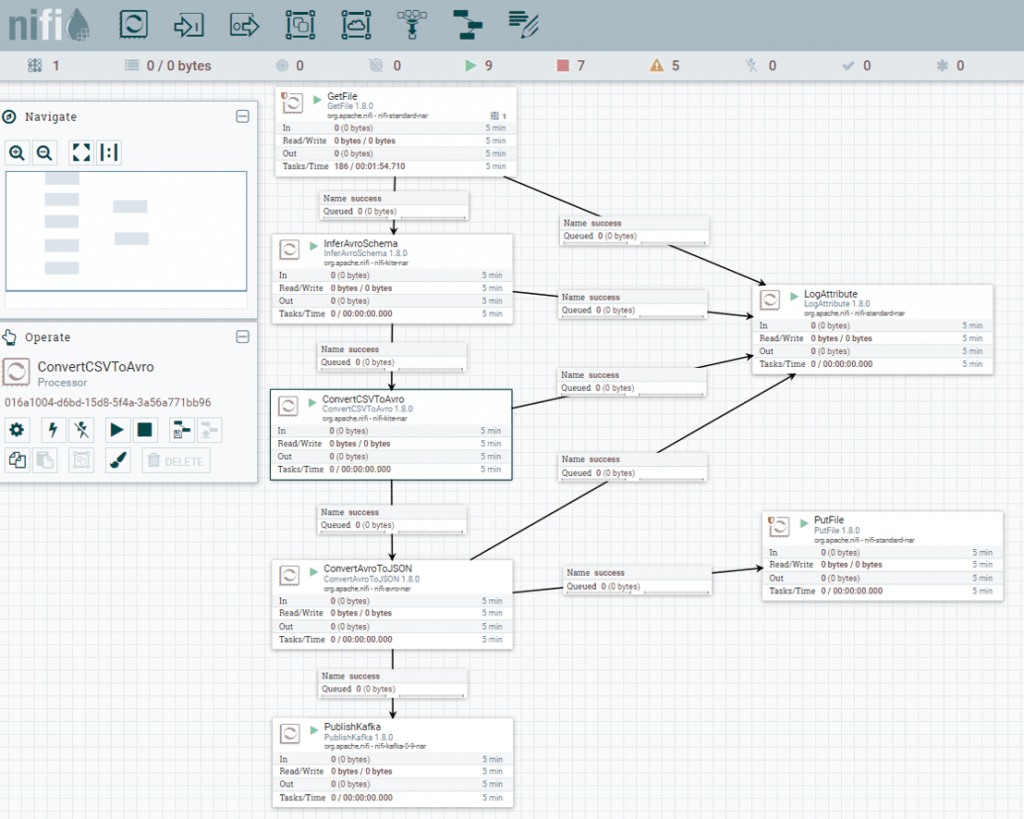
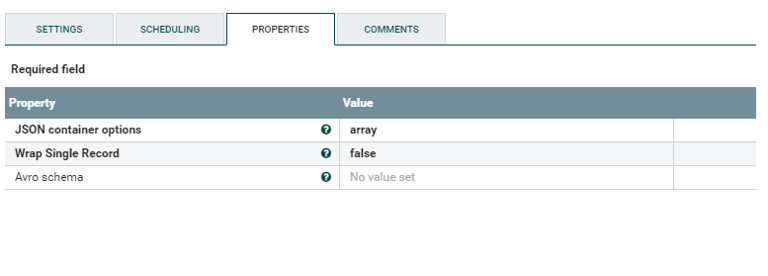
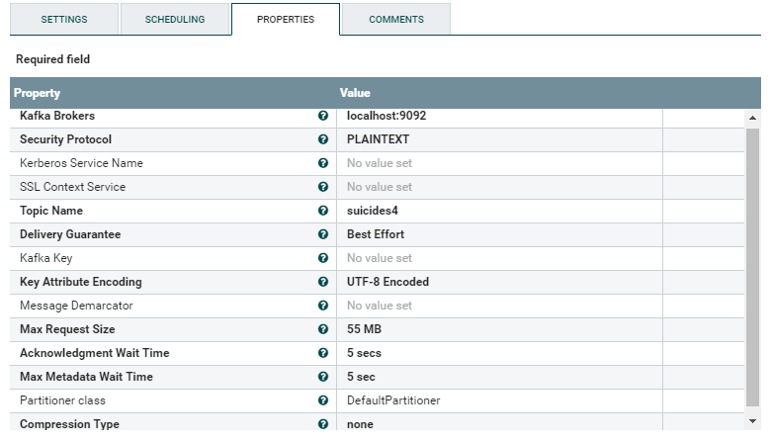
Apachi nifi를 이용해서 csv파일을 로드하고 json형태의 데이타로 data transform을 구현합니다.
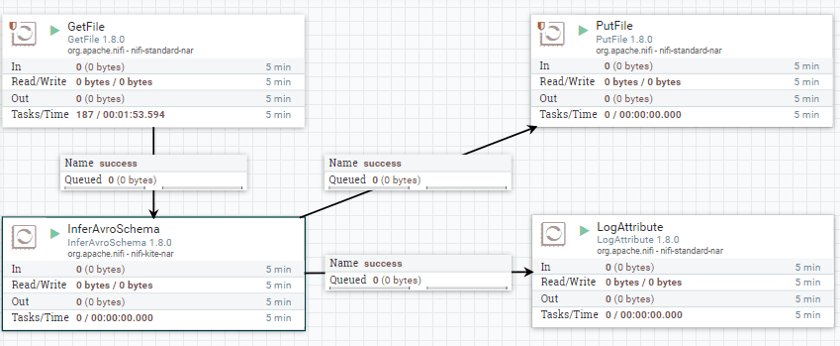
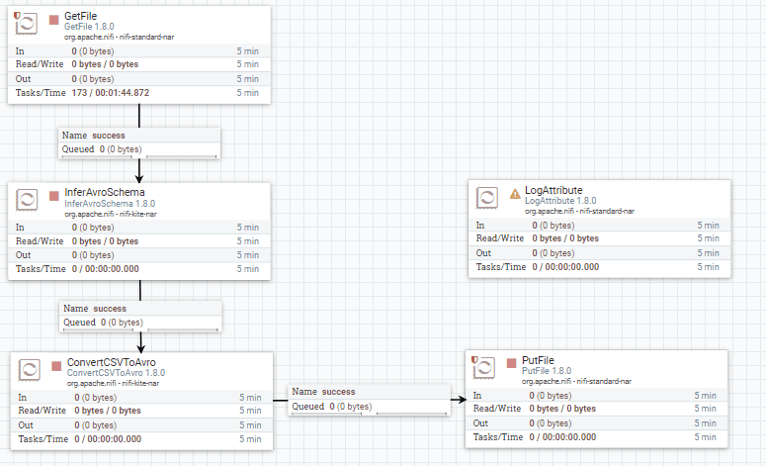
전체 분석 flow
#1 Dataset 개요
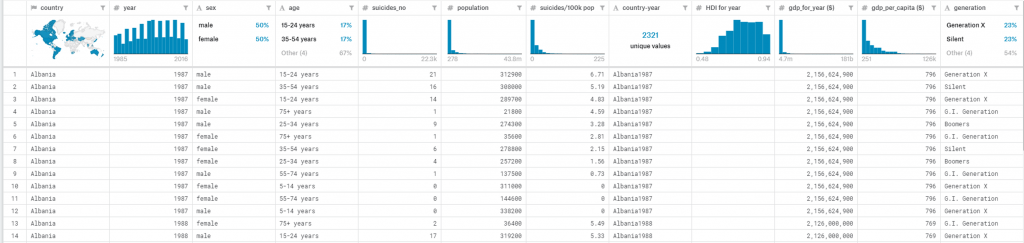
https://www.kaggle.com/russellyates88/suicide-rates-overview-1985-to-2016 시간,장소, 연령 등의 요소가 포함된 데이터 셋을 분석하여 자살율 증가를 예방함을 목적으로 합니다.
데이터 파일의 구성요소
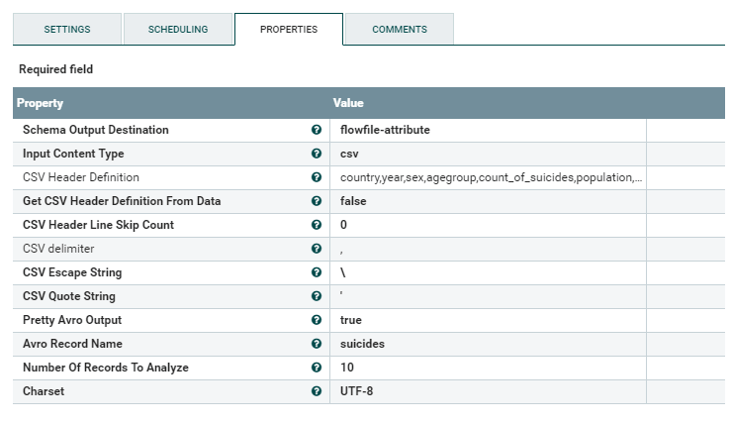
country, year, sex, age group, count of suicides, population, suicide rate, country-year composite key, HDI for year, gdp_for_year, gdp_per_capita, generation (based on age grouping average).
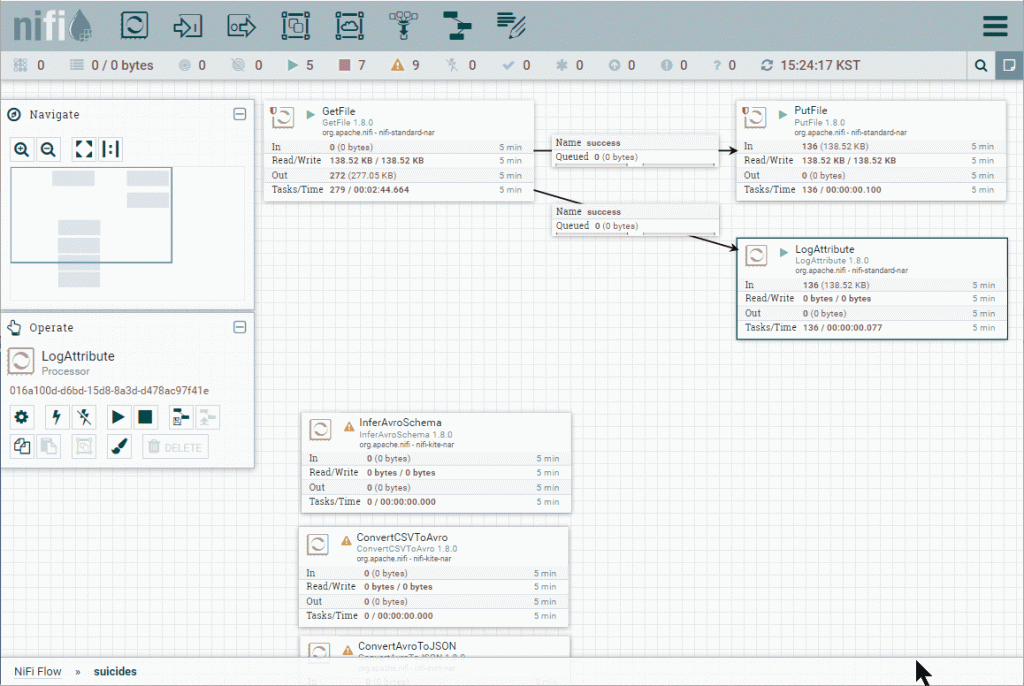
Apache NiFi 프로세서는 데이터 흐름을 만드는 블록입니다. 모든 프로세서는 출력 흐름 파일 생성에 기여하는 각각의 기능을 가지고 있습니다. 아래 이미지에 표시된 데이터 흐름은 GetFile 프로세서를 사용하여 한 sucides cvs 파일을 가져 와서 PutFile 프로세서를 사용하여 다른 디렉터리에 저장합니다.
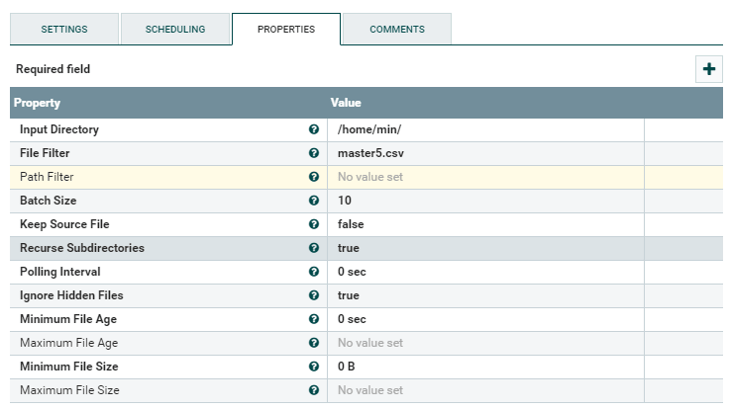
Input Directory, File Filter란에 수집대상 cvs파일의 Directory 및 파일명을 설정합니다.